In a major development for the field of large language models, Meta AI has released the first two versions of its next-generation Llama 3 series – an 8 billion parameter model and a 70 billion parameter model. These models demonstrate breakthrough capabilities across a wide array of benchmarks and real-world use cases.
At the core of Llama 3’s impressive performance are several key innovations and improvements over its predecessor Llama 2:
Architectural Advances: Llama 3 utilizes a more efficient 128K token vocabulary and leverages grouped query attention for faster inference, despite having increased model sizes.
Massive Training Data: The models were pre-trained on an unprecedented 15 trillion tokens of curated, high-quality data from public sources, including over 30 languages and a significant proportion of code.
Scaling Innovations: The team optimized Llama 3’s training process through extensive research on scaling laws, achieving log-linear improvements even after training on quintillions of tokens using highly parallelized systems.
Instruction Fine-Tuning: Leveraging techniques like rejection sampling, proximal policy optimization, and direct preference optimization on human preference rankings, Llama 3 excels at following instructions faithfully.
The results are stellar – Llama 3 sets new state-of-the-art performance records on numerous academic language model benchmarks like TriviaQA, OpenBookQA, and ANLI. Its coding abilities are also unmatched, achieving top scores on assessments like APPS, HumanEval, and CodeXGlue.
Perhaps more impressively, Llama 3 demonstrated superior performance in rigorous human evaluations across 12 major use cases such as reasoning, open-ended question answering, and creative writing. Human raters consistently preferred Llama 3’s outputs over same-scale models like GPT-3.
On the safety front, Llama 3 comes integrated with robust AI security tools. This includes the upgraded LlamaGuard 2 for controlling unsafe outputs, CyberSecEval 2 for preventing misuse, and a new CodeShield for filtering insecure code suggestions.
While the 8B and 70B versions are immensely capable, they are just the beginning. Meta has models scaling up to over 400 billion parameters currently in training, with early checkpoints already exhibiting remarkable multi-modal abilities like visual question answering.
Llama 3’s performance has been benchmarked against other leading models, showing significant improvements across various tasks:
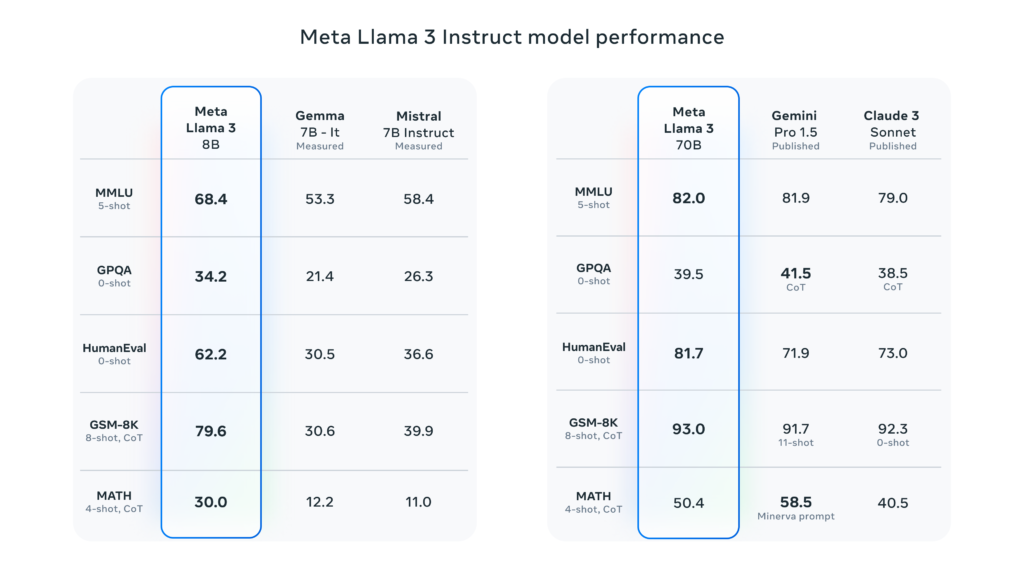
- MMLU (Multitask Language Understanding):
- Llama 3 70B: 75.1
- GPT-4: 86.4
- BBH (Big-Bench Hard):
- Llama 3 70B: 53.9
- GPT-4: 67.0
- GSM8K (Grade School Math 8K):
- Llama 3 70B: 74.8
- GPT-4: 92.0
These benchmarks demonstrate Llama 3’s strong performance in language understanding, complex reasoning, and mathematical problem-solving.
The release of Llama 3 marks a major milestone in large language model development. With state-of-the-art performance across myriad capabilities, robust safety integrations, and increasingly capable versions on the horizon, Llama 3 is poised to usher in a new wave of AI innovation and applications.